

The pressure from DeepSeek has finally reached Jensen Huang.
On the evening of January 27, Beijing time, Nvidia's stock price plummeted nearly 11% before the market opened, and with a current market value of $349.28 billion, Nvidia's market value is feared to shrink by more than $35 billion.
The low-cost large model training strategy initiated by DeepSeek is making the capital market doubt whether the high-end computing power chips represented by Nvidia are facing a new bubble when models with relatively less computing power can achieve performances not inferior to OpenAI.
This concern is further boosting the popularity of DeepSeek. Taking advantage of the release window of the new DeepSeek R1 model, in just one week by January 27, DeepSeek topped the free charts of both the US App Store and the China App Store.
It is worth mentioning that this is the first time an AI assistant product has surpassed OpenAI's ChatGPT and topped the US App Store.
The explosive user experience has directly led to service outages in DeepSeek within two days. Following a brief crash on January 26, on January 27, DeepSeek again briefly experienced a service outage with webpage/API unavailability. The official response stated that it might be related to service maintenance, request limitations, and other factors.
The new model DeepSeek R1 is undoubtedly the direct catalyst for this global discussion around DeepSeek. On January 20, DeepSeek officially released the R1, which matches the performance of the full version of OpenAI o1.
Under the bottleneck of the Scaling Law, where more data and better effects are reached, OpenAI released a new inference model o1 in September last year, adopting a new training method of RL (Reinforcement Learning), which is considered a "paradigm shift" in the field of large models.
However, until the release of DeepSeek R1, domestic large model manufacturers had not yet launched models that could benchmark against OpenAI o1. DeepSeek became the first player to crack OpenAI's technical black box.
More importantly, unlike OpenAI's closed-source approach and the paid usage restrictions of the o1 model, DeepSeek R1 is not only open-source but also freely available for unlimited global use.
The emergence of R1 not only breaks the industry consensus that flagship open-source models can only be driven by tech giants but also breaks another consensus formed last year: general-purpose large models are increasingly becoming a capital competition among big companies. DeepSeek created an R1 with performance comparable to o1 using less than one-tenth of OpenAI's resources.
The impact brought by DeepSeek and its users has already made some big companies uneasy.
Meta is the first to be affected. Known as the "king of large model open-source" in the industry, it has internally started to worry that its yet-to-be-released Llama 4 may not catch up with DeepSeek R1 in performance.

OpenAI, which is being comprehensively benchmarked, is also starting to feel the pressure. OpenAI CEO Altman not only grabbed attention by releasing the first intelligent agent Operator but also began to tease the upcoming news of the new o3-mini model.
It is foreseeable that the industry earthquake triggered by DeepSeek will affect not only foreign companies but also domestic giants.
One
As an open-source model, DeepSeek R1's performance in tasks such as mathematics, coding, and natural language reasoning is said to be comparable to the official version of the OpenAI o1 model.
In the AIME 2024 math benchmark test, DeepSeek R1 scored 79.8%, while OpenAI o1 scored 79.2%; in the MATH-500 benchmark test, DeepSeek R1 scored 97.3%, while OpenAI o1 scored 96.4%.
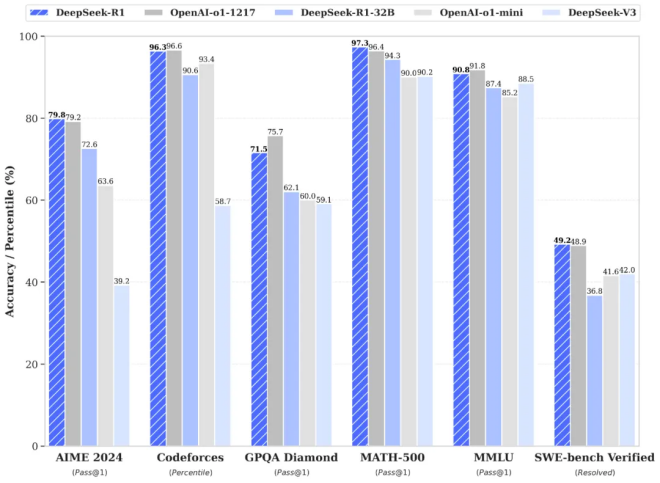
As an inference model, a key technical difference of DeepSeek R1 from OpenAI o1 lies in its innovative training method, such as the R1-Zero route used in the data training phase, which directly applies Reinforcement Learning (RL) to the base model without relying on Supervised Fine-Tuning (SFT) and labeled data.
Previously, OpenAI's data training heavily depended on human intervention, with its data team even structured into different levels of hierarchy. Large volumes of data with simple and clear labeling requirements were handed over to cheap outsourced labor in Kenya, while higher-level data was given to higher-quality labelers, many of whom were well-trained university PhDs.
The direct reinforcement learning route of DeepSeek R1 is like letting a genius child learn to solve problems purely through continuous attempts and feedback, without any examples or guidance.
Perplexity CEO Aravind Srinivas commented, "Necessity is the mother of invention. Because DeepSeek had to find a solution, they eventually created more efficient technology."
In addition, DeepSeek has also innovated in obtaining high-quality data.
According to DeepSeek's official technical documentation, the R1 model uses data distillation technology to generate high-quality data, improving training efficiency. Data distillation refers to a series of algorithms and strategies that denoise, reduce dimensions, and refine raw, complex data to obtain more refined and useful data.
This is also a key reason why DeepSeek can achieve performance comparable to the OpenAI o1 model with a smaller parameter size. AI expert Dr. Ding Lei told Alphabet List, "The size of the model parameters and the final model performance are not directly proportional but nonlinear... Having more data is just a qualitative aspect, but the team's data cleaning ability is more important, otherwise, as data increases, data interference will also grow."
More importantly, DeepSeek achieved the aforementioned results with less than one-tenth of the resources.
The DeepSeek-V3 open-source base model released at the end of last December has performance benchmarked against GPT-4o, but the official training cost is only 2048 Nvidia H800s, totaling about $5.576 million.
In contrast, the training cost of the GPT-4o model is about $100 million, using tens of thousands of Nvidia GPUs, and those are the more powerful H100s compared to the H800.
At that time, former OpenAI co-founder and head of Tesla's autopilot, Andrej Karpathy, stated that the capabilities of DeepSeek-V3 level usually require a cluster of nearly 16,000 GPUs.
Currently, DeepSeek has not yet announced the full cost of training the inference model R1, but the official has announced its API pricing: R1 costs 1 to 4 RMB per million input tokens and 16 RMB per million output tokens. In contrast, the operating cost of OpenAI o1 is about 30 times that of the former.
This performance has also led Scale AI founder Alexandr Wang to comment that the AI large model performance of the Chinese AI company DeepSeek is roughly equivalent to the best models in the United States. "Over the past decade, the United States may have been leading China in the AI race, but the release of DeepSeek's AI large model might 'change everything'."
a16z partner and AI large model Mistral board member Anjney Midha even said that from Stanford to MIT, DeepSeek R1 almost overnight became the preferred model for researchers at America's top universities.
Including Stanford University visiting professor of computer science Andrew Ng and Microsoft Chairman and CEO Satya Nadella, big names are also starting to pay attention to this new model from China.
In fact, this is not the first time DeepSeek has gone viral. Since announcing the formation of a team to develop large models, DeepSeek has twice sparked heated discussions, although previously more limited domestically.
In April 2023, the hundred-billion quantitative hedge fund giant Huanfang Quantitative announced that it would concentrate resources and efforts on artificial intelligence technology, establishing a new independent research organization to explore AGI (General Artificial Intelligence).
A month later, in May 2023, the organization was named "DeepSeek," and the first model, DeepSeek V1, was released. At that time, "Finance Eleven" reported that there were no more than five companies in China with over 10,000 GPUs, and DeepSeek was one of them, thus beginning to attract external attention.
By May 2024, DeepSeek once again became famous through a large model price war. At that time, DeepSeek released the DeepSeek V2 open-source model and was the first in the industry to cut prices, reducing the inference cost to only 1 RMB per million tokens, approximately one-seventieth of GPT-4 Turbo.
Subsequently, major companies such as ByteDance, Tencent, Baidu, and Alibaba followed suit with price cuts. The Chinese large model price war thus unfolded.
Two
The emergence of DeepSeek R1 further proves to the outside world that in the field of large models, especially general-purpose large models, startups still have opportunities.
In early January, Zero One Things founder Kai-Fu Lee officially stated that he would withdraw from the pursuit of AGI, focusing on industry models with small and medium parameters in the future. "From a business perspective, we believe that only large companies can continue to develop super-large models," said Kai-Fu Lee.
Investors are more aggressive than Kai-Fu Lee. Starting in 2023, as the managing partner of GSR Ventures, Zhu Xiaohu felt that large models were destroying startups because the three pillars of models, computing power, and data were all concentrated in large companies, seeing no opportunity for startups, and directly warned entrepreneurs not to blindly believe in general-purpose large models.
Cheng Hao of Yuanwang Capital even directly believes that the Chinese version of ChatGPT will only emerge from five companies: BAT+ByteDance+Huawei. In Cheng Hao's view, entrepreneurs can only outrun large companies if they have a first-mover advantage.
It was precisely because foreign giants like Google were not optimistic about OpenAI's large language model route that ChatGPT was able to run ahead with the momentum of being first. However, developing large models has now become a consensus among Chinese tech giants, with companies like Baidu and Alibaba launching products even faster than startups.
But in an interview with "Undercurrent," DeepSeek founder Liang Wenfeng responded to competition with large companies, saying, "Large companies definitely have advantages, but if they can't apply them quickly, they may not be able to persist because they need to see results. Top startups also have very solid technology, but like the old wave of AI startups, they all face the challenge of commercialization."
Backed by a hundred-billion quantitative fund, DeepSeek, without worrying about funding, chose a rather idealistic path, focusing only on model research without considering commercialization, and boldly starting with young people.
In DeepSeek's team of about 150, most are fresh graduates from top universities, PhD students in their fourth or fifth year who haven't graduated yet, and some young people who graduated only a few years ago.
This is a deliberate choice by Liang Wenfeng and one of the secrets why DeepSeek was able to launch the R1 model ahead of big companies. "If you pursue short-term goals, it's right to find experienced people. But if you look long-term, experience is not so important; foundational skills, creativity, and passion are more important," Liang Wenfeng explained.
This has also made DeepSeek the only Chinese large model startup that only focuses on basic models and does not consider commercialization for the time being, and also a company capable of continuing to open-source flagship models.
As of now, DeepSeek R1 has become one of the most downloaded large models on the open-source community Hugging Face, with over 100,000 downloads.
Previously, a faction led by Baidu founder Robin Li firmly believed that the open-source route could not compete with the closed-source route, and that open-source models lacking commercial support would fall further behind in future competitions.
But at least from the current perspective, the emergence of DeepSeek R1 proves that the open-source route can still catch up with the leading players in large models, and startups still have the ability to drive the development of the open-source ecosystem.
Meta AI Chief Scientist Yann LeCun commented in his evaluation, "To those who see DeepSeek's performance and think 'China is surpassing the US in AI,' your interpretation is wrong. The correct interpretation should be, 'Open-source models are surpassing proprietary models.'"
After the release of DeepSeek v3 last year, Liang Wenfeng stated that the company will not choose to move from open-source to closed-source like OpenAI in the future. "We believe it's more important to have a strong technical ecosystem first."
After all, OpenAI's experience at least shows that in the face of disruptive technology, closed-source cannot form a sufficient moat, nor can it prevent others from catching up. "So we place value on the team; our colleagues grow in this process, accumulate a lot of know-how, and form an innovative organization and culture, which is our moat," he said.
When GPT-3 was released in 2020, OpenAI detailed all the technical details of the model training. Wen Jirong, Executive Dean of the Gaoling School of Artificial Intelligence at Renmin University of China, believes that many large models in China actually have traces of GPT-3.
But as OpenAI gradually moved towards closure with GPT-4, some domestic large models lost the path they could follow to catch up.
Now, with the arrival of open-source R1 from DeepSeek, it will undoubtedly create a new reference path for domestic and foreign large model players in the development of inference models benchmarking against o1.
Three
The butterfly effect triggered by DeepSeek in the field of large models has already begun to affect some large companies.
A Meta employee posted a message on the Silicon Valley anonymous gossip sharing platform Blind, stating that Meta's generative AI department is in panic due to DeepSeek, even revealing that the new generation open-source model Llama 4, which has not yet been released, is already lagging behind DeepSeek in benchmark tests.
In further reports by foreign media, Meta's generative AI team and infrastructure team are forming four small combat teams to analyze DeepSeek at the pixel level, some trying to figure out how DeepSeek reduces training and operating costs, some responsible for researching the data DeepSeek might have used to train the model, and some considering new technologies to reorganize Meta's model based on the attributes of the DeepSeek model.
At the same time, to boost morale, Meta founder Zuckerberg has released new news about continuing to expand AI investment in 2025, stating that the overall expenditure around AI in 2025 will reach $60 billion to $65 billion, an increase of more than 70% compared to last year's $38 billion to $40 billion, thus building a supercomputer cluster with 1.3 million GPUs.
In addition to competing with Meta for the title of king of open-source, DeepSeek is also stealing customers from OpenAI.
Under the allure of API prices 30 times cheaper than OpenAI, some startups are switching allegiances. Steve Hsu, co-founder of enterprise-level AI agent developer SuperFocus, believes that DeepSeek's performance is similar to or even better than OpenAI's flagship model GPT-4, which supports most of SuperFocus's generative AI functions. "SuperFocus may switch to DeepSeek in the next few weeks, as DeepSeek can be downloaded for free, stored and run on its own servers, and will increase the profit margin of sales products," he said.
Becoming the model base for more companies is also the position that Liang Wenfeng plans for DeepSeek to occupy in the future. In Liang Wenfeng's view, DeepSeek can just be responsible for basic models and cutting-edge innovation in the future, while other companies build To B and To C businesses on the basis of DeepSeek. "If we can form a complete industrial upstream and downstream, we don't need to do applications ourselves," Liang Wenfeng said.
Domestically, research on DeepSeek is also being conducted simultaneously. Reports indicate that teams from ByteDance, Alibaba Tongyi, Zhipu, Kimi, and others are actively researching DeepSeek, with ByteDance even considering research cooperation with DeepSeek.
Before these companies, Lei Jun was one step ahead in poaching from DeepSeek. In December last year, Yicai reported that Lei Jun allegedly offered a multimillion annual salary to personally recruit "post-95 genius girl" Luo Fuli, a key developer of the DeepSeek-V2 open-source model. In the future, Luo Fuli may work at Xiaomi AI Lab, leading Xiaomi's large model team.
Beyond poaching, more intense competition domestically may also revolve around APIs. "Last year, a batch of startups and small and medium-sized enterprises in China turned to domestic large model companies due to OpenAI's supply cut, and now DeepSeek is very likely to become the barbarian that recovers OpenAI's lost ground," predicted Jiang Yi, founding partner of Hengye Capital.
The pressure is being transmitted to these domestic large model companies. If they cannot quickly catch up to the R1 level in model performance, customers are likely to vote with their feet.










